| Новости |
| Статьи |
| OLAP-каталог |
| Учебные курсы |
| Глоссарий |
| Рассылки |
| Download |
| Ссылки |
| Форум |
| Архив |
Частотный анализатор английских слов на Python 3, умеющий нормализовывать слова с помощью WordNet
Я учу английский и всячески упрощаю этот процесс. Как-то мне потребовалось получить список слов вместе с переводом и транскрипцией для определенного текста. Задача не была сложной, и я принялась за дело. Чуть позднее был написан скрипт на python, все это умеющий, и даже умеющий чуть больше, поскольку мне захотелось получить еще и частотный словарь из всех файлов с английским текстом внутри. Так вышел маленький набор скриптов, о котором я и хотела бы рассказать.
Работа скрипта заключается в распарсивании файлов, выделении английских слов, нормализации их, подсчете и выдачи первыx countWord слов из всего получившегося списка английских слов.
В итоговом файле слово записывается в виде:
[число повторений] [само слово] [перевод слова]
О чем будет дальше:
- Мы начнем с получения списка английских слов из файла (используя регулярные выражения);
- Дальше начнем нормализовывать слова, то есть приводить их с естественной формы в тот вид, в котором они хранятся в словарях (тут мы немного изучим формат WordNet);
- Затем мы подсчитаем количество вхождений у всех нормализованных слов (это быстро и просто);
- Дальше мы углубимся в формат StarDict, потому что именно с помощью него получим переводы и транскрипцию.
- Ну и в самом конце мы куда-нибудь запишем результат (я выбрала файл формата Excel).
Я использовала python 3.3 и надо сказать не один раз пожалела, что не пишу на python 2.7, поскольку часто не хватало нужных модулей.
Частотный анализатор.
Итак, начнем с простого, получим файлы, распарсим их на слова, подсчитаем, отсортируем, и выдадим результат.
Для начала составим регулярное выражение для поиска английских слов в тексте.
Регулярное выражение для поиска английских слов
Простое английское слово, например "over", можно найти, используя выражение "([a-zA-Z]+)" - здесь ищется одна или более букв английского алфавита.
Составное слово, к примеру "commander-in-chief", найти несколько сложнее, нам нужно искать идущие друг за другом подвыражения вида "commander-", "in-", после которых идет слово "chief". Регулярное выражение примет вид "(([a-zA-Z]+-?)*[a-zA-Z]+)".
Если в выражении присутсвует промежуточное подвыражение, оно тоже включается в результат. Так, в наш результат попадает не только слово "commander-in-chief", но также и все найденные подвыражения, Чтобы их исключить, добавим в начале подвыражеения '?:' стразу после открывающейся круглой скобки. Тогда регулярное выражение примет вид "((?:[a-zA-Z]+-?)*[a-zA-Z]+)". Нам еще осталось включить в выражения слова с апострофом вида "didn't". Для этого заменим в первом подвыражении "-?" на "[-']?".
Все, на этом закончим улучшения регулярного выражения, его можно было бы улучшать и дальше, но остановимся на таком:
"((?:[a-zA-Z]+[-']?)*[a-zA-Z]+)"
Реализация частотного анализатора английских слов
На этом, в сущности, работа с частотным словарем могла бы быть и закончена, но наша работа только начинается. Все дело в том, что слова в тексте пишутся с учетом грамматических правил, а это значит, что в тексте могут встретиться слова с окончаниями ed, ing и тд. По сути, даже формы глагола to be ( am, is, are) будут засчитываться за разные слова.
Значит до того, как слово будет добавлено в счетчик слов, нужно привести его к правильной форме.
Переходим ко второй части - написанию нормализатора английских слов.
Лемматизатор английских слов
Существуют два алгоритма - стемминг и лемматизация. Стемминг относится к эвристическому анализу, в нем не используются какие-либо базы. При лемматизации используются различные базы слов, а также применяются преобразования согласно грамматическим правилам. Мы для наших целей будем использовать лемматизацию, поскольку погрешность результата намного меньше, чем при стемминге.
Про лемматизацию уже было несколько статей на хабре, например вот и вот. Они используют базы aot. Мне не хотелось повторяться, а также было интересно поискать какие-нибудь другие базы для лемматизации. Я хотела бы рассказать проWordNet, на нем лемматизатор мы и построим. Начну с того, что на официальном сайте WordNet можно скачать исходники программы и сами базы данных. WordNet умеет очень много, но нам потребуется лишь малая часть его возможностей - нормализация слов.
Нам понадобятся только базы данных. В исходниках WordNet (на си) описан сам процесс нормализации, в сущности сам алгоритм я взяла оттуда, переписав на python. Ах да, разумеется для WordNet существует библиотека для python - nltk, но во-первых, она работает только на python 2.7, а во-вторых, насколько бегло я смотрела, при нормализации всего лишь посылаются запросы на сервер WordNet.
Общая диаграмма классов для лемматизатора:
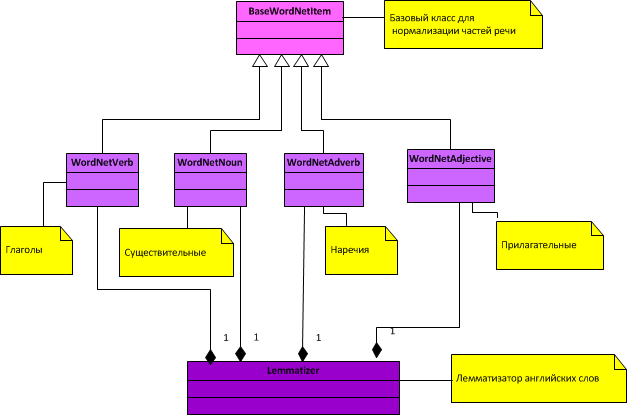
Как видно из диаграммы, нормализуются только 4 части речи (существительные, глаголы, прилагательные и наречия).
Если кратко описать процесс нормализации, то он заключается в следующем:
1. Для каждой части речи загружаются из WordNet по 2 файла - индексный словарь (имеет название index и расширение согласно части речи, например index.adv для наречий) и файл исключений ( имеет расширение exc и название согласно части речи, например adv.exc для наречий).
2. При нормализации сперва проверяется массив исключений, если слово там есть, возвращается его нормализованная форма. Если слово не является исключением, то начинается привидение слова по грамматическим правилам, то есть отсекается окончание, приклеивается новое окончание, затем слово ищется в индексном массиве, и если оно там есть, то слово считается нормализованным. Иначе применяется следующее правило и тд, пока правила не закончатся или слово не будет нормализовано раньше.
Классы для леммализатора:
Ну вот, с нормализацией закончили. Теперь частотный анализатор умеет нормализовывать слова. Переходим к последней части нашей задачи - получение переводов и транскрипции для английских слов.
Переводчик иностранных слов, использующий словари StarDict
Про StarDict можно писать долго, но основное преимущество этого формата то, что для него есть очень много словарных баз, практически на всех языках. На хабре еще не было статей на тему StarDict и пора восполнить это пробел. Файл, описывающий формат StarDict, обычно расположен рядом с самими исходниками.
Если отбросить все дополнения, то самый минимальный набор знаний по этому формату будет следующим:
Каждый словарь должен содержать в себе 3 обязательных файла:
1. Файл с расширением ifo - содержит непротиворечивое описание самого словаря;
2. Файл с расширением idx . Каждая запись внутри idx файла состоит из 3-х полей, идущих друг за другом:
- word_str - Строка в формате utf-8, заканчивающаяся '\0';
- word_data_offset -Смещение до записи в файле .dict (размер числа 32 или 64 бита);
- word_data_size - Размер всей записи в файле .dict.
3. Файл с расширением dict - содержит сами переводы, добраться до которых можно зная смещение до перевода (смещение записано в файле idx ).
Не долго размышляя над тем, какие классы в итоге должны получиться, я создала по одному классу для каждого из файлов, и один общий класс StarDict, объединяющий их.
Получившаяся диаграмма классов:
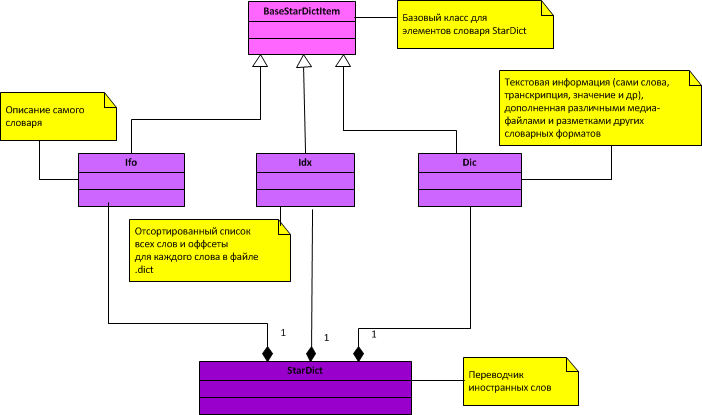
Классы для перводчика StarDict:
Ну вот, переводчик готов. Теперь нам осталось только объединить вместе частотный анализатор, нормализатор слов и переводчик. Создадим главный файл main.py и файл настроек Settings.ini.
Единственной сторонней библиотекой, которую нужно скачать и поставить дополнительно, является xlwt, она потребуется для создания файла в формате Excel (туда записывается результат).
В файле настроек Settings.ini для переменной PathToStarDict можно писать несколько словарей через ";". В этом случае слова будут искаться в порядке очередности словарей - если слово найдено в первом словаре, поиск заканчивается, иначе перебираются все остальные словари StarDict.
Послесловие
Все исходники, описанные в этой статье, можно скачать на github.
Напоминание:
- Скрипты писались под windows;
- Использовался python 3.3;
- Дополнительно нужно будет поставить библиотеку xlwt для работы с Excel;
- Отдельно нужно скачать словарные базы для WordNet и StarDict (у словарей StarDict нужно будет дополнительно распаковать запакованные в архив файлы с расширением dict);
- В файле Settings.ini нужно прописать пути для словарей и куда сохранить результат.
- Отдельно хотелось бы сказать про транскрипцию, она есть не во всех словарных базах StarDict, но найти словарь с транскрипцией по поиску в гугле не составит труда (во всяком случае я их легко находила).
| Рекомендовать | Обсудить материал | Написать редактору | Распечатать | Дата публикации: 11.03.2014 |