Вы находитесь на страницах старой версии сайта. Перейдите на новую версию OLAP.ru
|
Вы находитесь на страницах старой версии сайта. Перейдите на новую версию OLAP.ru |
| Поиск по сайту | ||||||
| Новости | ||||||
| Основы OLAP | ||||||
| Продукты | ||||||
| Business Objects/ Crystal Decisions | ||||||
| Каталог | ||||||
| OLAP в жизни | ||||||
| Тенденции | ||||||
| Download | ||||||
| ||||||
Временной ряд как объект хранения в СУБДАндрей Прохоров, Informix 1. ВведениеПодавляющее большинство потребителей информационных технологий в той или иной степени уже решили задачу оперативного ввода данных. При этом многие из них испытывают насущную необходимость в организации анализа накопленных данных. Одним из наиболее часто встречающихся объектов анализа являются временные ряды. С содержательной точки зрения временной ряд порождается в результате наблюдения за одним или несколькими параметрами какого-либо процесса. При наблюдении фиксируется значение этих параметров и привязывается к моменту наблюдения. В результате образуется последовательность измеренных значений, упорядоченная в хронологическом порядке. Такая последовательность и называется временным рядом [1]. За последние несколько десятилетий разработан обширный математический аппарат анализа временных рядов. Главные задачи этого аппарата заключаются в выявлении закономерностей в поведении наблюдаемого процесса и прогнозирование его поведения в будущем. Несмотря на глубокую теоретическую проработку методов анализа временных рядов, их практическая реализация в настоящее время встречает серьезные трудности. Одним из наиболее серьезных источников проблем является неспособность крупных промышленных реляционных СУБД (РСУБД) эффективно хранить и обрабатывать временные ряды [2]. Дело в том, что именно этот класс СУБД обеспечивает основу крупных корпоративных информационных систем. При этом они имеют все необходимые средства для описания временного ряда как одной из хранимых структур данных. Однако производительность обработки этой структуры данных оказывается столь низкой, а трудоемкость описания прикладной логики столь высокой, что на практике эти СУБД не используются для хранения и обработки временных рядов. Сейчас для решения задачи хранения и анализа временных рядов вместо РСУБД используются узкоспециализированные системы. Они избавлены от недостатков, свойственных РСУБД при работе с временными рядами. Однако, специализированные системы, в свою очередь, имеют ряд принципиальных ограничений:
В результате использование специализированных систем позволяет решить проблему эффективного хранения и обработки временных рядов только на первых порах, при относительно небольших объемах данных. Причем даже на начальном этапе пользователям приходится преодолевать серьезные трудности. Дело в том, что в подавляющем большинстве случаев анализ временных рядов является только одной из подзадач КИС. Интеграция закрытых специализированных систем в общую структуру корпоративной информационной системы требует значительных усилий. В настоящее время у многих пользователей возникает потребность в системе управления временными рядами (СУВР) удовлетворяющей следующим требованиям:
2. Проблемы хранения и анализа временных рядов в СУБДКак уже отмечалось ранее, практика показала, что РСУБД не способны в полной мере обеспечить эффективное хранение и обработку временных рядов. Возникает сложная задача интеграции средств эффективной работы с временными рядами при сохранения всех преимуществ РСУБД. Средства для решения данной проблемы предоставила объектно-реляционная технология. 2.1. Использование реляционной модели При первом рассмотрении не совсем очевидно, почему РСУБД не могут справится с такой простой структурой данных, как временной ряд. Ни для кого не секрет, что РСУБД хорошо зарекомендовали себя как основа для построения крупных информационных систем. Они с успехом применяются как для задач оперативной обработки информации, так и в системах поддержки принятия решений. Развитая математическая теория, лежащая в основе логической модели базы данных, хорошо отработанная технология и наличие поддерживаемых промышленных стандартов способствовали широкому распространению РСУБД. Однако задачи хранения и анализа временных рядов не стали очередной успешной областью применения РСУБД. В лучшем случае РСУБД используют для хранения временных рядов в виде больших двоичных объектов (BLOB). При этом ей отводятся выполнение только двух операций - положить BLOB и извлечь BLOB [2]. В результате мощный и сложнейший инструмент используется как самое примитивное устройство. Главная причина неэффективной работы РСУБД с временными рядами заключается в плохой совместимости основ реляционной модели и природы временного ряда. Одной из фундаментальных основ реляционной модели является понятие отношения - неупорядоченного множества кортежей [3]. Напротив, принципиальным свойством временного ряда является упорядоченность его элементов. Некоторые производители РСУБД вводят в свои продукты средства оптимизации работы с упорядоченными последовательностями. Так широкое распространение получили кластерные индексы. При построении такого индекса записи на диске упорядочиваются в соответствии со значениями ключей индекса. Данный подход позволяет оптимизировать доступ к данным, но все проблемы применения реляционной модели к временным рядам при этом не снимаются. В качестве классического примера рассмотрим ведение торгов ценными бумагами. Предметом анализа является регистрация сделок: время сделки, код ценной бумаги, объем и цена. Согласно всем канонам проектирования реляционных баз данных необходимо создать таблицу очень простой структуры.
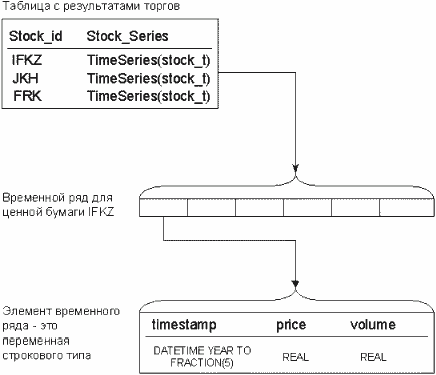
Записи поступают в хронологическом порядке по мере совершения сделок по любой из бумаг. Однако для анализа временного ряда используются данные, относящиеся только к одному объекту или ценной бумаге, значительно реже производятся манипуляции с несколькими рядами одновременно. Таким образом, из таблицы будут извлекаться записи, относящиеся к одной ценной бумаге по порядку возрастания или убывания отметок времени. Проанализируем эффективность доступа к данным в описанной таблице. Длина строки невелика - несколько десятков байт, поэтому в одной странице данных СУБД может помещаться порядка сотни записей. В большинстве приложений количество временных рядов одной структуры также бывает порядка ста. Получается, что при очень грубой оценке для каждого временного ряда записи распределены примерно по одной на каждую страницу дискового пространства. Значит, чтобы выбрать записи, относящиеся к одному временному ряду, необходимо обратиться практически к каждой странице данных. Очень часто на практике размер таблицы значительно превосходит размер буферов СУБД. В такой ситуации практически каждое обращение к элементу временного ряда потребует подкачки с дисковых накопителей новой страницы данных. В таком режиме эффективность индексированного доступа практически сводится к нулю, поскольку основное время занимают операции ввода вывода с дисковой подсистемы. Ситуация может улучшится, когда необходимо извлечь не весь временной ряд, а только элементы попадающие в определенный временной интервал. В этом случае индекс помогает ограничить количество извлекаемых страниц данных. Необходимо обратить внимание, что при использовании индексного доступа к элементам временного ряда по аналогичным причинам происходит сканирование значительной части индексного дерева. Здесь удается избежать прохода по всему индексному дереву за счет построения сцепленного индекса по коду ценной бумаги и времени сделки. В таком сцепленном индексе ключи, относящиеся к одному временному ряду, будут локализованы в одном месте дерева. Это позволит последовательно пройти по ключам индекса, относящимся к запрошенному пользователем интервалу времени. Однако, в начале каждого ключа содержится код ценной бумаги. Наличие этого кода увеличивает размер индекса, замедляет поиск и, особенно сильно, вставку новых записей. Таким образом, индекс хоть и может помочь при выборке элементов ряда, попадающих в один временной интервал, но в целом работает малоэффективно. Очевидна необходимость выделения записей, относящихся к одному временному ряду в отдельную область хранения. При использовании классической реляционной структуры это можно сделать только отведя под каждый временной ряд отдельную таблицу. Но тогда для обращения к конкретному временному ряду придется задавать имя таблицы как параметр, т. е. придется использовать динамический SQL. Далеко на все инструментальные средства в принципе поддерживают возможность работы с динамическим SQL (например SQLJ level 0). Кроме того, динамический SQL сильно затрудняет разработку и замедляет выполнение программ. К тому же большое количество таблиц, соответствующее количеству временных рядов в базе данных, сильно усложняет администрирование СУБД. 2.2. Использование объектно-реляционной модели Принципиальным обличием объектно-реляционной СУБД от классической РСУБД заключается в поддержке концепции абстрактного типа данных. При этом разработчик имеет возможность описать структуру нового типа данных и переделить методы для манипулирования этой структурой. В настоящий момент коммерческие и исследовательские проекты по созданию СУБД, способной эффективно работать с временными рядами, сосредоточено на применении объектно-реляционной технологии. Получаемый в последние годы опыт эксплуатации коммерческих продуктов использующих объектно-реляционную технологию подтверждает перспективность данного направления. Первым на рынке коммерческих продуктов, использующих объектно-реляционную технологию, стал модуль Time Series DataBlade компании Illustra. Он был призван дополнить возможности одноименной ОРСУБД средствами работы с временными рядами. После приобретения Illustra компанией Informix этот модуль был переработан для использования уже в ОРСУБД Informix. Данный модуль вводит в ОРСУБД новый тип данных - TimeSeries [4]. После этого в таблицах можно создавать колонки нового типа. Так, например, если вернуться к рассмотренному ранее примеру с журналом биржевых сделок, то структура таблицы принимает следующий вид.
Физически размещать длинный временной ряд вместе с обычными полями таблицы не рационально. Поэтому для хранения временных на дисковом пространстве сервера выделялась отельная область. В результате логическая модель временного ряда принимает вид, изображенный на Рис. 1.
Рис. 1.Структура типа данных TimeSeries в Informix TimeSeries DataBlade Недостатком объектно-реляционной реляционной модели является то, что клиентские инструментальные средства должны понимать новые структуры данных. Для решения этой проблемы на базе таблицы с типом данных TimeSeries может быть создана псевдо-таблица. Эта таблица будет иметь структуру, соответствующую классической реляционной модели (см. таблица в разделе 2.1). При этом все обращения прозрачно для пользователя будут транслироваться к объектной структуре. В результате даже инструментальные средства, понимающие только типы данных SQL 2, смогут работать с временными рядами, используя все преимущества в производительности от новой физической модели данных. Примечательно, что большинство методов анализа временных рядов разработано для регулярных временных рядов. В таких рядах интервал между наблюдениями фиксирован. Если исходный наблюдаемый процесс порождает нерегулярный временной ряд, то на его основе строится набор регулярных рядов с различными интервалами, которые в последствии и анализируются. Фиксированный интервал между наблюдениями позволяет оптимизировать физическую модель хранения временного ряда. При этом отметки времени могут быть заменены целочисленным индексом - наблюдение под номером таким-то. Задав момент начала наблюдения и интервал между ними, можно элементарным способом определить преобразование целочисленного индекса в отметку времени и обратно. Поддерживая расположение элементов временного ряда в хронологической последовательности, появляется возможность на основе целочисленного индекса однозначного определять положения любого элемента. В результате вообще отпадает необходимость поддерживать индекс по отметкам времени для регулярного временного ряда. Концепция абстрактного типа данных позволяет скрыть от пользователя все манипуляции. Внутренние механизмы становятся абсолютно прозрачным для пользователя. Следует отметить, что во многих случаях целочисленный индекс занимает меньше места при хранении на диске, чем полная отметка времени. В результате на диске временной ряд хранится в очень компактном виде. Это повышает скорость доступа к данным. Даже в случае нерегулярного ряда такая модель имеет преимущество пред классической реляционной моделью, т. к. нет необходимости сохранять идентификатор временного ряда с каждым его элементом. 2.3. Выводы Применение концепции абстрактного типа данных позволяет определить логическую и физическую модель хранения временного ряда, обладающую следующими преимуществами по сравнению с классической реляционной моделью:
3. ЗаключениеРазвитие объектно-реляционной технологии предоставило промышленным РСУБД возможность вторгнутся в очередную закрытую для них прежде сферу обработки временных рядов. Это вторжение позволяет не только достичь возможностей доступных ранее только специализированных систем, но и привносит новые перспективы развития для данной прикладной области. Список литературы
© 2001 Interface Ltd |