Вы находитесь на страницах старой версии сайта. Перейдите на новую версию OLAP.ru
|
Вы находитесь на страницах старой версии сайта. Перейдите на новую версию OLAP.ru |
| Поиск по сайту | ||||||
| Новости | ||||||
| Основы OLAP | ||||||
| Продукты | ||||||
| Business Objects/ Crystal Decisions | ||||||
| Каталог | ||||||
| OLAP в жизни | ||||||
| Тенденции | ||||||
| Download | ||||||
| ||||||
Проектирование хранилищ данных на платформе INFORMIX с помощью PLATINUM ERwinСергей Маклаков, Interface Ltd Хранилища данных (Data Warehouse) представляют собой специализированные базы данных, предназначенные для хранения данных, которые редко меняются, но на основе которых часто требуется выполнение сложных запросов. Обычно они ориентированы на выполнение аналитических запросов, которые обеспечивают поддержку принятия решений для руководителей и менеджеров. Хранилища данных позволяют разгрузить промышленные базы данных, и тем самым, позволяют пользователям более эффективно и быстро извлекать необходимую информацию. Как правило, хранилища данных оперируют с огромными объемами информации, что предъявляет к их проектированию и реализации повышенные требования. Выбор в качестве платформы хранилища данных такой высокопроизводительной СУБД, как Informix, позволяет существенно повысить общую эффективность создаваемой информационной системы. В этом случае ERwin (CASE-средство фирмы PLATINUM technology. inc.) становится незаменимым инструментом, поскольку с одной стороны эффективно поддерживает на физическом уровне проектирование объектов Informix, с другой стороны имеет специализированные средства моделирования хранилищ данных. Ниже рассматриваются основные возможности ERwin по проектированию хранилищ данных. К проектированию хранилищ данных обычно предъявляются следующие требования:
Эти требования существенно отличают структуру реляционных СУБД и хранилищ данных. Нормализация данных в реляционных СУБД приводит к созданию множества связанных между собой таблиц. В результате, выполнение сложных запросов неизбежно приводит к объединению многих таблиц, что существенно увеличивает время отклика. Проектирование хранилища данных подразумевает создание денормализованной структуры данных (допускается избыточность данных и возможность возникновения аномалий при манипулировании данными), ориентированной в первую очередь на высокую производительность при выполнении аналитических запросов. Нормализация делает модель хранилища слишком сложной, затрудняет ее понимание и ухудшает эффективность выполнения запроса. Для эффективного проектирования хранилищ данных ERwin использует размерную (Dimensional) модель. Dimensional - методология проектирования, специально предназначенная для разработки хранилищ данных. ERwin поддерживает методологию размерного моделирования благодаря использованию специальной нотации для физической модели – Dimensional. Наиболее простой способ перейти к нотации Dimensional - при создании новой модели (меню File / New) в диалоге ERwin Teamplate Selection выбрать из списка предлагаемых шаблонов DIMENSION. В шаблоне DIMENSION сделаны все необходимые для поддержки нотации размерного моделирования настройки, которые, впрочем, можно установить вручную. Моделирование Dimensional сходно с моделированием связей и сущностей для реляционной модели, но отличается целями. Реляционная модель акцентируется на целостности и эффективности ввода данных. Размерная (Dimensional) модель ориентирована в первую очередь на выполнение сложных запросов к БД. В размерном моделировании принят стандарт модели, называемый схемой звезда (star schema), которая обеспечивает высокую скорость выполнения запроса посредством денормализации и разделения данных. Невозможно создать универсальную денормализованную структуру данных, обеспечивающую высокую производительность при выполнении любого аналитического запроса. Поэтому схема звезда строится так, чтобы обеспечить наивысшую производительность при выполнении одного самого важного запроса, либо для группы похожих запросов. Схема звезда обычно содержит одну большую таблицу, называемую таблицей факта (fact table), помещенную в центр, и окружающие ее меньшие таблицы, называемые таблицами размерности (dimensional table), соединенными c таблицей факта в виде звезды радиальными связями. В этих связях таблицы размерности являются родительскими, таблица факта - дочерней. Схема звезда может иметь также консольные таблицы (outrigger table), присоединенные к таблице размерности. Консольные таблицы являются родительскими, таблицы размерности - дочерними. В размерной модели, ERwin обозначает иконкой роль таблицы в схеме звезда:
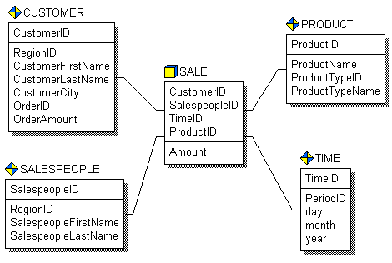
Прежде чем создать базу данных со схемой типа звезда, необходимо проанализировать бизнес-правила предметной области, с целью выяснения центрального вопроса, ответ на который наиболее важен. Все прочие вопросы должны быть объединены вокруг этого основного вопроса и моделирование должно начинаться с этого основного вопроса. Данные, необходимые для ответа на этот вопрос, должны быть помещены в центральную таблицу модели - таблицу факта. Например, если необходимо создавать отчеты об общей сумме дохода от продаж за период, или по типу товара, или по продавцам, следует разрабатывать модель так, чтобы каждая запись в таблице факта представляла общую сумму продаж, для каждого клиента за определенный период времени для каждого продавца (рис.1). В примере, таблица факта содержит суммарные данные о продажах (“SALE”), а таблицы размерности содержат данные о заказчике и заказах (“CUSTOMER”), продуктах (“PRODUCT”), продавцах (“SALESPEOPLE”) и периодах времени (“TIME”).
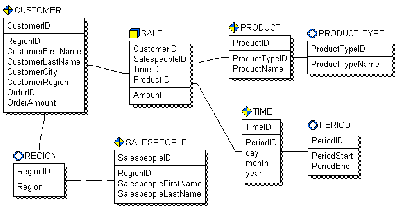
Рис.1. Схема звезда. Таблица факта является центральной таблицей в схеме звезда. Она может состоять из миллионов строк и содержать суммирующие или фактические данные, которые могут помочь ответить на требуемые вопросы. Она соединяет данные, которые хранились бы во многих таблицах традиционных реляционных базах данных. Таблица факта и таблицы размерности связаны идентифицирующими связями, при этом первичные ключи таблицы размерности мигрируют в таблицу факта в качестве внешних ключей. В размерной модели направления связей явно не показываются – они определяются типом таблиц. Первичный ключ таблицы факта целиком состоит из первичных ключей всех таблиц размерности. В примере (таблица факта “SALE”) первичный ключ составлен из четырех внешних ключей: CustomerID, SalespeopleID, TimeID и ProductID. Таблицы размерности имеют меньшее количество строк, чем таблицы факта и содержат описательную информацию. Эти таблицы позволяют пользователю быстро переходить от таблицы факта к дополнительной информации. В примере на рис. 1, таблица “SALE” - таблица факта; “CUSTOMER”, “TIME”, “SALESPEOPLE” и “PRODUCT” - таблицы размерности, которые позволяют быстро извлекать информацию о том, кто и когда сделал покупку, какой продавец и на какую сумму продал и ,какие именно товары были проданы. ERwin поддерживает использование вторичных таблиц размерности, называемых консольными (outrigger) таблицами, хотя они не требуются для схемы звезда. Консольные таблицы могут быть связаны только таблицами размерности, причем консольная таблица в этой связи родительская, а таблица размерности - дочерняя. Связь может быть идентифицирующей или неидентифицирующей. Консольная таблица не может быть связана таблицей факта. Она используется для нормализации данных в таблицах размерности. Нормализация данных полезна при моделировании реляционной структуры, но она уменьшает эффективность выполнения запросов к хранилищу данных. В размерной модели главной целью является обеспечение высокой эффективности просмотра данных и выполнения сложных запросов. Схема снежинка обычно препятствует эффективности, потому что требует объединения многих таблиц для построения результирующего набора данных, что увеличивает время выполнения запроса. Поэтому при проектировании не следует злоупотреблять созданием множества консольных таблиц. Когда консольные таблицы используются в размерной модели, для нормализации каждой таблицы размерности, модель называется снежинка (рис. 2).
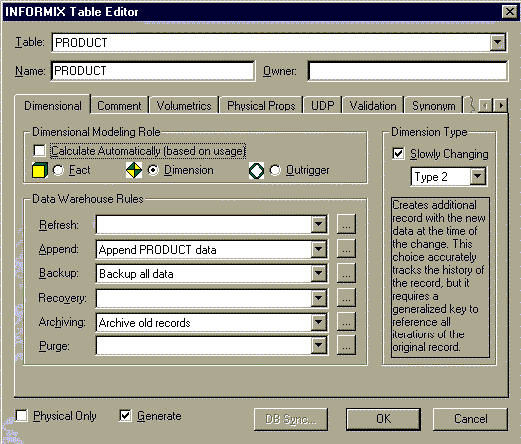
Рис.2. Схема снежинка. В диалоге описания свойств таблицы INFORMIX Table Editor имеется закладка Dimensional, в которой задаются специфические свойства таблицы в размерной модели (рис. 3).
Рис. 3. Закладка Dimensional диалога INFORMIX Table Editor. Роль таблицы в схеме (Dimensional Modeling Role). По умолчанию Erwin автоматически определяет роль таблицы на основании созданных связей (таблица факта, размерности или консольная). Таблица без связей определяется как таблица размерности, таблица факта не может быть родительской в связи, таблица размерности может быть родительской по отношению к таблице факта, консольная таблица может быть родительской по отношению к таблице размерности. При ручном назначении роли таблицы ERwin автоматически проверяет корректность размерной модели и выдает диалог с предупреждающим сообщением в случае следующих нарушений синтаксиса:
Тип таблицы размерности (Dimension Type). Каждая таблица размерности может содержать неизменяемые, либо редко изменяемые данные (slowly changing dimensions). Поскольку хранилище данных имеет ненормализованную структуру, редактирование таблиц размерности может привести к коллизиям. Для того, чтобы избежать противоречий при хранении данных, ERwin позволяет задать тип редко изменяемых данных, который отличается способом редактирования данных:
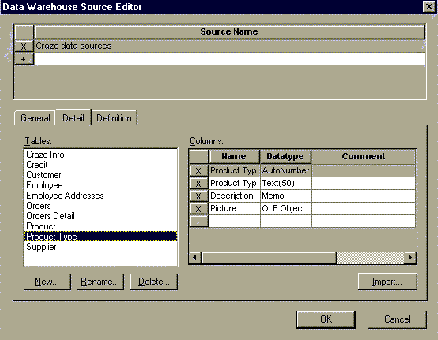
Правила хранения данных (Data Warehouse Rules). Для каждой таблицы можно задать шесть типов правил манипулирования данными: обновление (Refresh), дополнение (Append), резервное копирование (Backup), восстановление (Recovery), архивирование (Archiving) и очистка (Purge). Для задания правила следует выбрать имя правила из соответствующего списка выбора. Каждое правило должно быть предварительно описано в диалоге Data Warehouse Rule Editor (меню Edit / Data Warehouse Rule). Для каждого правила должно быть задано имя, тип, определение. Например, определение правила дополнения данных может включать частоту и время дополнения (ежедневно, в конце рабочего дня), продолжительность операции и т.д. Связать правила с определенной таблицей можно с помощью диалога Table Editor. При проектировании хранилища данных важно определить источник данных (для каждой колонки), метод, которым исходные данные извлекаются , преобразовываются, и фильтруются прежде, чем они импортируются в хранилище данных. Хранилище данных может объединять информацию из текстовых файлов и многих баз данных, как реляционных (в том числе других БД на платформе Informix), так и нереляционных, в единую систему поддержки принятия решений. Чтобы поддерживать регулярные обновления и проверки качества данных, необходимо знать источник для каждой колонки в хранилище данных. Для документирования информации об источниках данных используется редактор Data Warehouse Source Editor (рис.4.).
Рис.4. Диалог Data Warehouse Source Editor. Имена таблиц и колонок источников данных могут быть импортированы как из баз данных (обратное проектирование), так и из других моделей ERwin. Каждому источнику может быть задано имя и определение. В редакторе Column Editor необходимо внести информацию об использовании источников данных для каждой колонки таблиц хранилища данных, а так же дополнительную информацию о способах, режимах и периодичности переноса данных из источника в хранилище данных. © 2001 Interface Ltd |