Вы находитесь на страницах старой версии сайта. Перейдите на новую версию OLAP.ru
|
Вы находитесь на страницах старой версии сайта. Перейдите на новую версию OLAP.ru |
| Поиск по сайту | ||||||
| Новости | ||||||
| Основы OLAP | ||||||
| Продукты | ||||||
| Business Objects/ Crystal Decisions | ||||||
| Каталог | ||||||
| OLAP в жизни | ||||||
| Тенденции | ||||||
| Download | ||||||
| ||||||
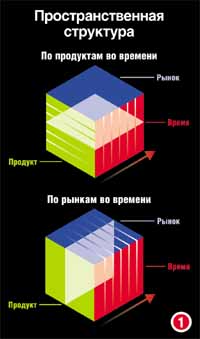
Проектирование киоска данныхГабриель Ганьон В настоящее время киоски данных - самый популярный и успешно применяемый тип хранилищ данных. Узкая специализация, поэтапный подход к проектированию и внедрению, высокая доходность инвестированного капитала делают их одинаково привлекательными для работающих в условиях жесткой конкуренции пользователей из сферы бизнеса, перегруженных специалистов по информационным технологиям и экономных менеджеров. Подобно большинству хранилищ данных, киоски представляют собой системы поддержки принятия решений. Их отличие от более крупных хранилищ состоит в ограниченности информационного диапазона, обеспечивающего потребности одного подразделения или бизнес-процесса. Благодаря такой узкой специализации киоски данных можно строить значительно быстрее, чем полномасштабные корпоративные хранилища данных, для планирования и анализа которых зачастую требуются годы. При условии согласованного форматирования данных киоски можно даже связывать друг с другом, организуя распределенные корпоративные хранилища данных. (Такой метод проектирования хранилищ иногда называется "восходящим" - bottom-up.) Действительно, многие разработчики рекомендуют такой поэтапный подход, поскольку для завершения всего проекта может потребоваться несколько лет, а отдельные киоски можно подготовить в очень сжатые сроки и сразу же получить ощутимые выгоды. Независимо от поставленной цели - построение подразделенческого информационного канала, который навсегда останется автономным, или организации интегрированного хранилища данных для предприятия в целом - существуют фундаментальные принципы проектирования киосков данных, отличающиеся от применяемых в системах оперативной обработки информации. OLTP и OLAPКиоски данных не похожи на системы OLTP (Online Transactional Processing - оперативная обработка транзакций), обслуживающие повседневную деятельность предприятия. Они представляют собой системы поддержки принятия решений, позволяющие аналитикам предприятий выявлять тенденции, проводить сравнения и прогнозировать будущие результаты. Эти функции часто называют оперативным анализом данных (Online Analytical Processing - OLAP). Системы OLTP не могут непосредственно выполнять функции OLAP. В частности, в системах OLTP хранится только "моментальный снимок" самой последней оперативной информации; для анализа OLAP требуется знание предыстории транзакций за длительный период времени. Системы OLTP непрерывно обновляются и иногда содержат пропуски и ошибочные данные; для OLAP требуются статические, исчерпывающие данные, с исправленными ошибками. И наконец, системы OLTP обрабатывают тысячи (подчас миллионы) транзакций в день; системы OLAP выполняют только одну транзакцию за один цикл загрузки - когда данные в систему загружаются в пакетном режиме, - но могут охватить тысячи одновременно поступающих запросов в день. (Некоторые специалисты считают и запросы транзакциями, но мы не разделяем этого мнения. В результате транзакции база данных переходит из одного стабильного состояния в другое, что подразумевает изменение.) Эти различия в функциях находят отражение в структурных различиях. В системах OLTP обычно используется модель связи сущностей-объектов, знакомая администраторам реляционных баз данных. В этой модели данные нормализуются с целью минимизации избыточности; она оптимальна для ввода и обновления данных. А системы OLAP редко обновляются пользователями и в основном служат для ответов на запросы и составления отчетов. Вполне допустимо проектировать киоски данных на основе модели связи сущностей-объектов, но многие эксперты отдают предпочтение пространственной модели, данные в которой организованы так, чтобы упростить их извлечение; такая модель оптимальна для составления отчетов. Пространственная модельПри построении пространственной модели для некоторого бизнес-процесса, в частности маркетинга или сбыта, информация представляется (упорядочивается) по координатным осям (измерениям), например по продуктам или регионам продаж. Пространственная модель выглядит так гиперкуб или многомерный массив (рис. 1). Из рисунка видно, что пользователи могут делать плоскостные срезы и выделять блоки данных любым образом. Величины, хранящиеся в массиве, называются фактами (facts) и используются как количественные показатели, характеризующие деятельность предприятия. Описания фактов называются измерениями (dimensions) и служат в качестве ограничителей или заголовков рядов.
В киоске, предназначенном для анализа информации о продажах, факты могут представлять число проданных единиц продукции или общий объем продаж, а измерениями могут быть названия продуктов или адреса торговых точек. Поскольку аналитики в сфере бизнеса рассматривают данные во временном контексте, в качестве одного из измерений обычно выбирается время. Каждый блок гиперкуба представляет собой значение. Значения можно отыскивать по любому измерению или комбинации измерений. В нашем примере анализа продаж можно подсчитать число изделий, проданных в течение последнего года, просуммировав данные об объемах продаж по времени. Если вы хотите узнать, какой из региональных отделов продаж показал лучшие результаты, можно провести поиск по регионам и найти максимальную величину общего объема продаж. Некоторые инструменты OLAP работают с нереляционными пространственными базами данных, но многие применимы к реляционным базам данных, спроектированным в соответствии с принципами пространственной модели. Продукты OLAP, предназначенные для таких баз данных, называются инструментами ROLAP (Relational OLAP - реляционная OLAP).
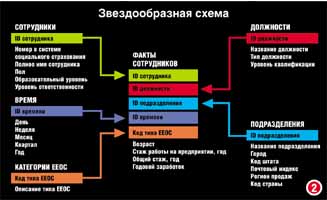
Звездообразная схемаПространственная модель, реализованная в реляционной системе, называется схемой звездообразного объединения или, коротко, звездообразной схемой (рис. 2). В звездообразной схеме все измеряемые атрибуты содержатся в одной центральной таблице фактов (fact tables). Все остальные таблицы представляют собой таблицы измерений (dimension tables), содержащие описательные атрибуты. Ключ (или уникальный идентификатор) таблицы фактов составлен из всех ключей таблиц измерений. В результате таблица фактов соединяется со всеми таблицами измерений. Но таблицы измерений соединены только с таблицей фактов. (На диаграмме отношений таблица фактов располагается в центре, а таблицы измерений - на исходящих из центра лучах, образующих рисунок звезды; отсюда и название схемы.) Благодаря простоте звездообразной схемы процедура извлечения данных очень эффективна и нравится конечным пользователям, которым не приходится перемещаться по лабиринтам связей. Рассмотрим этапы проектирования звездообразного киоска данных. Построение киоска данных по звездообразной схемеВыбор анализируемого бизнес-процесса. Первый шаг при проектировании киоска данных - выбор моделируемого бизнес-процесса. Бизнес-процесс - это набор связанных действий, обеспечивающих выполнение бизнес-функции, например маркетинга или управления складскими запасами. Определите круг вопросов, которые будут интересовать пользователей киоска. Сотрудники группы продаж, вероятно, захотят сравнить результаты своей работы с показателями конкурентов. Специалисты отдела маркетинга пожелают сравнить эффективность различных маркетинговых мероприятий. Определение фактов и измерений. Определив круг вопросов, ответы на которые должны содержаться в киоске, можно выбрать факты и измерения, максимально облегчающие поиск ответов. Факты какого типа наиболее эффективны и каким образом отличить факт от измерения? Факты - элементы, которые могут быть измерены и проанализированы. Ральф Кимболл, крупнейший авторитет в области пространственного моделирования, лучшими фактами считает "числовые, представленные последовательным рядом значений, и аддитивные". Числовые факты - это количественные величины. (К ним не относятся такие элементы, как регистрационные номера в системе социального страхования или почтовые индексы, которые могут классифицироваться как числовые типы данных ради единообразия подходов к интерпретации данных.) Над числовыми фактами допускается выполнение различных математических операций; их легко измерить.
Фактом, представленным последовательным рядом значений (continuously valued), может быть любая из набора величин; обычно она часто изменяется. Если подсчитать число порций мороженого, проданных в течение одного часа в жаркий летний день, а затем повторить подсчет часом позже, то, скорее всего, результаты будут разными. Нельзя узнать значение, не произведя измерения, и, таким образом, число порций мороженого - пример факта, представленного последовательным рядом значений. Факты, представленные последовательно выбранными значениями, полезны, поскольку всегда содержат новую информацию. (Не имеет смысла отслеживать неизменную величину.) Аддитивный факт может суммироваться по всем измерениям. Например, в нашем киоске анализа данных о продажах, представленном на рис. 1, число проданных порций мороженого - аддитивный факт, поскольку путем сложения можно узнать, сколько порций продано на прошлой неделе (по времени); сколько порций продано в Калифорнии (по регионам); сколько продано порций шоколадного мороженого (по продуктам). Кимболл отдает предпочтение аддитивным фактам, потому что с их помощью можно получить компактные наборы результатов. Число записей, просматриваемых по запросам к исторической базе данных, может достигать нескольких тысяч, так что суммировать их содержимое - ценная возможность. Числовые, представленные последовательным рядом значений, и аддитивные элементы почти всегда помещаются в таблицы фактов, но не все факты обязательно должны соответствовать этому критерию. Некоторые факты полуаддитивны (semiadditive). Их можно корректно суммировать по одним измерениям, но нельзя по другим. Например, имеет смысл суммировать складские запасы по продуктам или по регионам, но не по времени. (Бессмысленно прибавлять к числу коробок ванильного мороженого, имеющихся в наличии сегодня, число коробок, имевшихся на прошлой неделе.) Полуаддитивные факты нельзя суммировать по всем измерениям, но их можно оценивать другими способами. Средняя величина складских запасов во времени имеет смысл, как и максимальный и минимальный уровни запасов и некоторые другие статистические показатели. И наконец, существуют неаддитивные (nonadditive) факты. Эти факты невозможно суммировать ни по одному из измерений. Пример числового неаддитивного факта - отношение. Неаддитивны и нечисловые факты. Неаддитивные факты нельзя суммировать, но их можно сосчитать, поэтому они измеримы. Неаддитивные факты чаще группируются с измерениями. Как уже отмечалось, измерения - описательные атрибуты, служащие в качестве ограничителей при запросах или заголовков рядов в отчетах. В звездообразной схеме измерения также представлены таблицами, содержащими такие атрибуты. Измерения, как правило, текстовые, относительно статичные и неаддитивные. Примеры измерений - имя сотрудника и регистрационный номер в системе социального страхования. Человек может сменить имя, но частые изменения маловероятны, и этот элемент обычно не относится к числу измеряемых. Вместо этого он несет информацию об измеряемой величине в таблице фактов, такой, к примеру, как повышение оплаты труда служащих. Не всегда можно легко отличить факты от измерений (координатных осей). Иногда в таблице осей могут содержаться числовые, аддитивные элементы, такие, как цена единицы товара. А иногда статические и неаддитивные элементы удобно разместить в таблице фактов. Все зависит от назначения конкретного киоска. Например, пол человека обычно относится к измерениям - это текстовый, статичный и неаддитивный элемент. Но если вы проектируете киоск, посвященный человеческим ресурсам, и аналитики часто задают вопросы типа "Каково соотношение между числом сотрудников мужского и женского пола, занимающих руководящие должности?", то пол можно поместить в таблицу фактов. Иногда даже специалисты не могут прийти к согласию, к какой категории следует отнести тот или иной элемент. Определение структурной единицы. Следующий шаг - определение структурной единицы (зерна). Зерно (grain) - нижний уровень детализации данных, хранящихся в киоске.
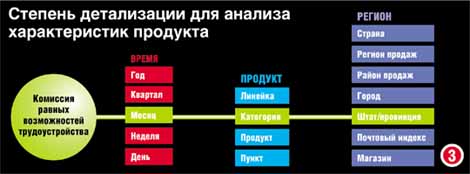
Информация может суммироваться на различных уровнях в соответствии с иерархической структурой (рис. 3). Ежедневные продажи могут суммироваться по неделям, месяцам или годам; проданные товары можно суммировать по продуктам, категориям продуктов или линейкам продуктов. Иногда применимы более одной иерархической системы. Магазины можно группировать по почтовым регионам с одинаковыми тарифами на пересылку или по территориям со схожей структурой продаж для проведения маркетинговых кампаний. Допустимо размещение обеих иерархий в одном измерении (по одной оси). Пользователи киосков могут работать с различными уровнями суммируемых данных. Вопрос заключается в следующем: в какой степени детализации нуждается пользователь? Всегда существует вероятность того, что какой-то пользователь в своем поиске пожелает дойти до базовой транзакции, и на основании этого можно прийти к выводу, что разработчик киоска всегда должен обеспечить самый низкий уровень детализации, но обычно в этом нет необходимости, а на практике зачастую неудобно. Если у компании имеется 1 млн. клиентов и каждый потребитель совершает 10 транзакций в месяц, то за пять лет число транзакций достигнет 600 млн. Если предположить, что каждая транзакция - это 200 байт, то только для транзакций потребуется 1,2 Тбайт памяти. Для анализа трендов может потребоваться 10 и более лет работы в оперативном режиме, и минимальные требования к памяти в этом случае составят 2,4 Тбайт. Таким образом, даже очень маленький файл транзакций с течением времени может стать очень большим. Если добавить агрегированные суммарные данные и индексы, то размеры киоска данных могут удвоиться и даже утроиться. Прежде чем приобретать дисковые запоминающие устройства с информационной емкостью, измеряемой петабайтами, внимательно обдумайте те вопросы относительно деятельности вашей фирмы, на которые вы хотите получать ответы, и соответственно выберите степень детализации данных. Сотрудникам розничного магазина, желающим отследить изменения складских запасов, нет нужды сохранять в киоске данные о каждой покупке; покупки можно суммировать на уровне продуктов. Но если вы хотите проанализировать поведение потребителей, то потребуется информация об отдельных покупках (а также способ связи конкретных пользовательских профилей с записями). Иногда выбор степени детализации определяется интенсивностью изменений: для отслеживания заработной платы служащих в течение длительного периода времени не имеет смысла использовать в качестве "зерна" день или неделю, поскольку оплата труда сотрудников пересматривается один раз в год. Табличная организация измерений. Определив степень детализации, можно установить остальные атрибуты таблицы измерений. В киоске исторических данных в качестве одного из измерений обязательно присутствует время, и в таблицу измерений необходимо поместить информацию о единицах времени, подходящих для данного киоска. Дни, недели, месяцы и годы, очевидно, необходимы, если степень детализации соответствует уровню ежедневных транзакций. Если требуются итоговые цифры за месяц или год, то, вероятно, для организации таблицы потребуются лишь такие единицы времени, как годы и месяцы. Финансовые киоски удобно дополнить кварталами, а в системах по учету людских ресурсов - использовать флажки для обозначения отпусков. В данной статье дан весьма общий обзор киосков данных и их применений. Мы лишь поверхностно коснулись некоторых проблем, таких, как учет изменений, происходящих во времени, и даже не упомянули о способах выбора ключей. Но мы надеемся, что общее представление о проблемах, возникающих при проектировании киосков данных, разбудит вашу любознательность и подтолкнет вас к дальнейшему изучению предмета. © 2001 Interface Ltd |