Вы находитесь на страницах старой версии сайта. Перейдите на новую версию OLAP.ru
|
Вы находитесь на страницах старой версии сайта. Перейдите на новую версию OLAP.ru |
| Поиск по сайту | ||||||
| Новости | ||||||
| Основы OLAP | ||||||
| Продукты | ||||||
| Business Objects/ Crystal Decisions | ||||||
| Каталог | ||||||
| OLAP в жизни | ||||||
| Тенденции | ||||||
| Download | ||||||
| ||||||
Подсистема сопоставления записей в хранилище данныхДмитрий Орлов, ВведениеДанная статья рассчитана на разработчиков информационных систем, специализирующихся в области обработки и хранения данных. В статье излагаются принципы проектирования и работы подсистемы сопоставления записей (далее - подсистема) хранилища данных, предназначенной для реальной интеграции данных, поступающих из различных информационных систем. Сопоставление записей (record linkage) - задача достаточно нетривиальная и, что немаловажно, мало описанная в русскоязычной технической литературе, так что данная статья является попыткой в какой-то мере восполнить этот пробел. Предпосылки создания подсистемыПри интеграции данных из нескольких независимых информационных систем в хранилище данных (далее ХД) возникает необходимость однозначной идентификации экземпляров некоторых сущностей - иначе говоря, перед разработчиком встает задача сопоставления записей (record linkage). Само существование такой задачи обусловлено следующими факторами:
Наверняка каждый разработчик хоть раз в своей практике подвергался воздействию этих факторов и задавал вопрос: "Как с этим бороться?" Один из возможных ответов на этот вопрос - разработка в ХД подсистемы сопоставления записей. Цели и принципы проектирования подсистемыЦелиДля начала необходимо определиться с целями, которые преследует создание подсистемы сопоставления записей. В нашем случае цели сформулированы следующим образом:
Цели достаточно прозрачны и очевидны, так что можно перейти к рассмотрению принципов проектирования. Принципы проектирования подсистемыФормулирование принципов - важный этап в проектировании любой системы (не только информационной), т.к. все последующие выводы и решения будут приниматься на их основе [1]. В нашем случае принципы проектирования подсистемы выглядят следующим образом:
Ознакомившись с принципами проектирования можно переходить к описанию работы подсистемы. Как работает подсистемаПри инициализации подсистемы необходимо произвести некоторые начальные действия, которые включают в себя процесс формирования и обработки эталонных наборов, а так же преобразование данных рабочих наборов. Эти операции будем считать вспомогательными и в контексте собственно процесса сопоставления рассматривать не будем2. Подсистема работает по принципу трехступенчатого фильтра, т.е. имеет в своем составе три ступени "фильтрации"3 данных:
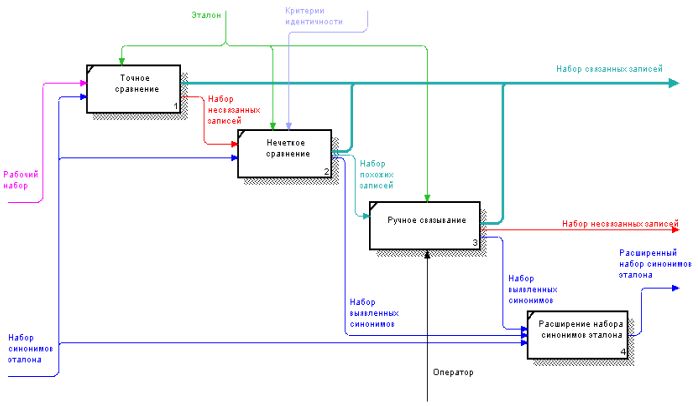
По завершении рабочих стадий необходимо произвести расширение набора синонимов эталона за счет вновь выявленных, на втором и третьем этапе, связей "эталон-рабочий образец" (согласно п.7). Расширение словаря синонимов возможно реализовать, как дополнительную функцию GUI программы, используемой оператором на стадии ручного связывания, либо как хранимую процедуру (stored procedure). Хочется подчеркнуть, что расширение словаря синонимов играет ключевую роль в подсистеме, т.к. во время следующего сеанса загрузки данных в ХД, нагрузка на оператора значительно уменьшится, либо дело вообще не дойдет до стадии ручного связывания, т.к., возможно, все необходимые связи будут обнаружены уже на стадии точного сравнения! IDEF0 диаграмма процессаНа диаграмме процесса средствами IDEF0, по сути, изложено то, о чем уже говорилось выше. Но все же, не помешают некоторые дополнительные пояснения.
Рис.1 IDEF0 диаграмма процесса сопоставления записей Во-первых, интерпретация набора синонимов, как ресурса, подлежащего преобразованию [4] вполне обоснована, учитывая наличие (и важность!) стадии расширения набора синонимов, несмотря на то, что логически он является частью эталона. Во-вторых, обязательно должен последовать вопрос, что это за набор несвязанных записей на выходе? Вопрос закономерный, и существуют, как минимум, три ответа на него:
Автор при испытании прототипа подсистемы получил на выходе такой набор, и хотя записей было достаточно мало, что делало его пригодным для ручного связывания (около десятка записей), попробовал пропустить его еще раз через стадию нечеткого сравнения с менее строгими условиями. Это дало определенный эффект - несколько записей "нашли" свои эталоны, но были и неверные соответствия. Так что, в принципе, возможно применение повторного цикла нечеткого сравнения с более мягкими критериями, при наличии на выходе несвязанных записей. Критерий качестваКак говорилось выше, подсистема должна минимизировать участие человека в процессе сопоставления. Исходя из этого и определим критерий качества подсистемы4 - минимальное число итераций с участием оператора, позволяющее достичь полного сопоставления рабочего набора с эталоном. Другими словами - это скорость расширения набора синонимов до уровня, включающего все элементы рабочего набора. Методы нечеткого сравненияРазобравшись с принципом работы подсистемы легко заметить, что основной вклад в эффективность работы подсистемы вносит именно стадия нечеткого сравнения. О том, как осуществлять нечеткий поиск и сравнение, написано достаточно много [5,7,8], однако большинство алгоритмов невозможно5 адаптировать к особенностям РСУБД. Рассмотрим вкратце два основных метода, которые достаточно просто реализовать с использованием языка SQL. Метод Q-грамЭто самый простой и очевидный метод, который, тем не менее, может показать хорошие результаты для некоторых видов данных, например географических названий. Критериями, в данном случае, могут служить следующие величины:
Судя по опытным данным, наиболее оптимальным является деление на подстроки длины Q = 2 (би-грамы). Рассмотрим пример: Таблица 1. Исходные данные
Количество Q-грам в строке рассчитывается по следующей формуле:
К = Длина строки - Q + 1 В случае би-грам для эталона эта величина равна 19, а для рабочей строки 16. Сами би-грамы приведены в таблице 2. Таблица 2. Би-грамы
Теперь можно продемонстрировать, как результат сравнения зависит от критерия идентичности, в очередной раз подчеркнув важность и сложность задачи по формированию критериев. Определим два различных критерия идентичности:
КИ1 = Количество совпадений/ Кэталона Для нашего случая они таковы (количество совпадений не учитывает повторяемость подстроки ТА): КИ1 = 14/19 = 0.73 Допустим, что для положительного решения о схожести строк величина критерия должна превышать некое пороговое значение, например - 0.75. Тогда, согласно критерию КИ1 - строки разные, а для КИ2 - похожие. В общем, есть простор для творчества. Основными достоинствами данного метода являются его простота и легкость реализации. Кроме того, он позволяет находить похожие строки с различным порядком слов. Недостатком же является необходимость работать с огромным количеством записей - Q-грамами. Метод хэшированияМетод хэшировния построен на принципе преобразования исходной строки в некий суррогатный код - хэш (hash), посредством некоторой функции (хэш-функции). В идеале при таком преобразовании схожие строки имеют одинаковый хэш, что и позволяет их сопоставить. Хэш-алгоритмы традиционно использовались и используются для связывания записей, в чем можно убедиться, ознакомившись с альманахом Федерального Комитета США по методам статистики, посвященному сопоставлению записей [8]. В этом альманахе описано достаточно много различных методов, так что автор рекомендует потратить время на его изучение. Самыми известными хэш-преобразованиями являются алгоритмы Soundex [2] и MetaPhone. Алгоритм MetaPhone адаптирован к особенностям русского языка Петром Каньковски из Новосибирска и прекрасно описан в его статье [6], где можно познакомиться с реализацией данного алгоритма на VB. Заметим, что такой алгоритм преобразования можно реализовать и средствами SQL. Итак, при наличии функции преобразования, генерирующей общий хэш для похожих строк, процесс сравнения сводится к хэш-трансформации эталонов (синонимов) и рабочих строк и их последующего строгого сравнения. Строки, которые имеют одинаковый хэш, считаются похожими. Все достаточно просто, если не учитывать затраты на подбор подходящей функции преобразования. Возможности оптимизацииКачество нечеткого сравнения можно улучшить, если работать не с фразами, а с отдельными словами, составляющими эти фразы. Здесь есть два пути оптимизации:
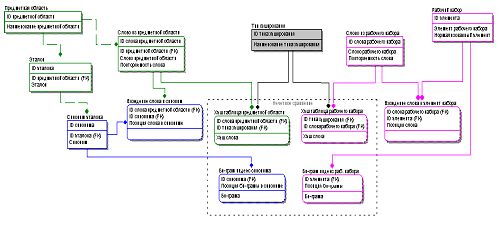
Естественно, что вышесказанным возможности оптимизации не исчерпываются и здесь остается пища для ума и открывается простор для эксперимента. ER диаграмма подсистемыСтоит напомнить, что одной из целей создания подсистемы является условие ее реализации средствами РСУБД. Исходя из этого условия, была спроектирована некоторая типовая структура РБД, обеспечивающая работоспособность подсистемы и позволяющая использовать всю мощь языка SQL для сопоставления записей. Логическая схема этой базы данных представлена в виде IDEF1X диаграммы и содержит следующие сущности: Таблица 3. Сущности подсистемы
Рис.2 IDEF1X диаграмма подсистемы сопоставления записей На диаграмме видно, что существуют две формально несвязанные8 области, предназначенные для хранения и обработки трансформированных данных эталонного набора и множества рабочих наборов. Собственно, цель подсистемы воссоздать связи между этими областями, оперируя обычными SQL-запросами. Таким образом, вся работа по связыванию записей, возлагаемая на РСУБД, сводится к трем этапам:
Результирующие таблицы для подобных запросов на диаграмме не указаны, т.к. они являются вспомогательными и могут иметь различную реализацию9 , что зависит от размеров наборов, используемой платформы и предпочтений разработчика. Повышение эффективности подсистемы за счет использования доменных знанийДо сих пор речь шла о сопоставлении линейных наборов, сущности рассматривались без учета возможных иерархических отношений - доменных знаний. Однако, можно значительно улучшить эффективность подсистемы, если в процессе связывания записей использовать эти доменные знания. Этот подход применим в случае, если сравниваемые сущности принадлежат некоторой иерархии, что делает возможным использование косвенной идентификации [9]. Так, сравнивая рабочий набор со справочником ОКАТО10 , где есть некая иерархия, можно использовать знания о принадлежности некоторого подмножества административно-территориальных единиц какому-либо административному центру. Рассмотрим это на примере Московской области: Таблица 4. Сравнение рабочего набора с ОКАТО
Очевидно, что попытавшись сравнить непосредственно наименования административного центра, мы получим отрицательный результат, в то время как сравнив подчиненные объекты можно с большой долей вероятности говорить о том, что это - один и тот же административный центр, т.к. в обоих случаях набор подчиненных объектов схож. Варианты применения подсистемыТеперь вкратце о том, как может использоваться подобная подсистема в ХД. Самой очевидной и, безусловно, важной областью применения подсистемы является, конечно же, интеграция данных из разных подсистем. Можно долго говорить о важности правильного сопоставления записей из различных источников - в конце концов, все сведется к следующему: "В хранилище данных недопустимо наличие логических дубликатов записей". И это так. Однако есть и некоторые другие аспекты применения данной подсистемы:
Все эти задачи достаточно актуальны, так что стоит приложить усилия для их решения. ГлоссарийЛогическая идентичность экземпляров сущности - экземпляры сущности, описывающие один и то же объект реального мира. Эталонный набор (эталон) - набор записей, однозначно трактуемых и синтаксически верных, покрывающий все пространство значений соответствующей предметной области, предназначенный для передачи этих свойств рабочим наборам. Эталонным набором может быть, как стандартный справочник (ISO, ОК11*), так и некий набор записей, полученный из информационной системы и обладающий вышеперечисленными свойствами. Набор синонимов - набор записей, являющихся установленными (подтвержденными) синонимами эталонного набора. Рабочий набор - набор записей, требующий сопоставления эталонному набору. Как правило, является входным набором данных, получаемых из внешней информационной системы. Набор связанных записей - набор записей, содержащий информацию о принадлежности конкретной записи рабочего набора определенной записи эталонного набора. Данный набор является результатом удачного сопоставления. Набор несвязанных записей - подмножество записей рабочего набора, в котором не удалось сопоставить ни одной записи эталонному набору. Набор выявленных синонимов - набор синонимов эталонного набора, сформированный в результате нечеткого сравнения и ручного связывания записей. Данный набор предназначается для расширения набора синонимов эталона. Критерий идентичности - формальное условие схожести двух строк (записей), которое может быть выражено в виде аддитивной величины. Предметная область - множество объектов, рассматриваемых в пределах данного контекста. Под контекстом, в данном случае, понимается множество всех возможных значений (терминов). Доменные знания - знания об иерархических отношениях сущностей и правилах формирования значений их атрибутов. Нормализация строки - трансформация строки, включающая в себя удаление символов, не входящих в алфавит, замену групп пустых символов на один пустой символ, приведение к общему регистру. Данная трансформация позволяет повысить инвариантность представления строки. Источники информации
1 - В данном контексте имеется ввиду не алфавит естественного языка, а набор символов, которые будут участвовать в процессе сравнения, что подразумевает возможность расширения или сужения данного алфавита по сравнению с естественным. © 2001 Interface Ltd | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||